Node js로 크롤링 하기

첫 포스트는 Node js로 크롤링(crawling)하기이다.
사실 Node js설치부터 이것저것 기초적인 것도 좋지만 그런것은 이미 많으니… 내가 열심히 찾으면서 했던 것들을 공유해 보고자 한다.
먼저 크롤링이 무엇일까 부터 알아보자.
CRAWLING
크롤링[crawling] : 무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술.
처음 내가 크롤링에 대한 설명을 들었을 때 내가 하려는 게 이 크롤링인가? 싶었다.
크롤링이라 함은 보통 긁는다라는 표현으로, 내가 원하는 정보를 어떠한 기술로 가져오는 거라고 생각했었다.
몇가지 정의를 더 살펴보자.
웹 크롤링 : 콘텐츠를 수집하기 위해 자동으로 웹사이트를 방문하는 프로세스.
웹 크롤러 : 자동으로 웹 페이지를 방문해 콘텐츠를 가져오고 URL을 추출. 다른 이름으로 웹 스파이더, 봇 또는 자동화 색인기 등.
자 이제 내가 하고 싶은 일이 나온 듯 하다. 난 웹 크롤러를 만들고 싶었던 것이다. 흔히 검색 엔진에서 사용하는 것이 크롤링 봇의 개념이였고, 뜬 구름 잡던 크롤링의 뜻에 있어서 확실히 알게 되었다. 다만, 한가지 생각할 것은 크롤링을 쓰는 목적은 반복작업을 덜기 위한것이 크다. 크롤링은 당연히 사람 손으로 해도되는데, 효율이 너무 떨어지기에 프로그래밍으로 대체하는 게 크다고 생각한다.
Node js 에서?
처음 Node js에서 크롤링을 해보자 라고 생각했을 때, 가장 먼저 든 생각은 할수 있을까? 였다.
그치만 바로 생각을 부정 했던건, 모든 언어는 상황에 따라 달리 쓰지만, 모든 상황에 있어서 굳이 못할 꺼는 없다는 말이였다.
PYTHON
개인적으로 아직 파이썬을 공부 해본 적은 없다.
주변에서 “중학생을 가르칠 때, 파이썬 부터 가르치면 접근성이 높아 좋아하더라” 같은 이야기를 들었는데, 얼마나 파이썬이 좋은 언어인지 대변해 주는 말이였다.
흔히, CRAWLING에 있어서 파이썬을 많이 언급한다. 파이썬의 SCRAPY를 쓰면, 쉽게 접근이 가능하기 때문이다. Node js에서도 SCRAPY 모듈을 설치해서 사용할 수 있지만, 이번에는 그 부분까지는 가지 않기로 했다.
시작!

이제 본격적으로 시작해 보겠다.
Node js가 다 깔려 있을 꺼라는 전제로 시작을 하므로, 혹시나 Node js 설치 조차 못했다면, 여기에서 설치 법을 보고 설치하길 바란다.
일단 목적을 정하자.
음.. 이전에 크롤링했을 때는 좀더 다양하고 많은 정보를 가져와서 썼었다(크롤링이 불법적인 역할이 될 수도 있으니 항상 조심하자.)`
API가 있는 것들은 (11번가, 네이버검색)사실 그리 어렵지 않다.
추후에 기본 포스팅이 끝난 후 예시로써 넣어볼 것이고, 지금은 내 블로그로 작업을 해볼까 한다.
사실, 상업적인 목적도 아니고, 기술을 설명하기에 적합하다고 느끼는 건 많지만 혹시나 문제가 될까봐 가장 안전한 내 것으로 정했다.
내 블로그는 포스팅도 몇개 없고, 너무 간단하다.
LISTING이 어플의 뷰가 대부분인 배달의 민족이나 YAP과 같은 음식업체나 의류업체를 예시로 한다면 참 좋을텐데 아쉽다..
리스팅의 네트워크를 크롬으로 따서, 내가 원하는 자료를 집어내는 통쾌함이 있는데… 하여튼
이제 진짜 시작해보자.
KOOCCI`s BLOG
내 블로그는 지금 이렇게 생겼다.
정말 못난 블로그지만.. 조만간 새단장을 하겠다..
하여튼 이런 블로그 인데, 우리가 알수 있는 것들은 무엇일까?
크롬을 활용해 보자.
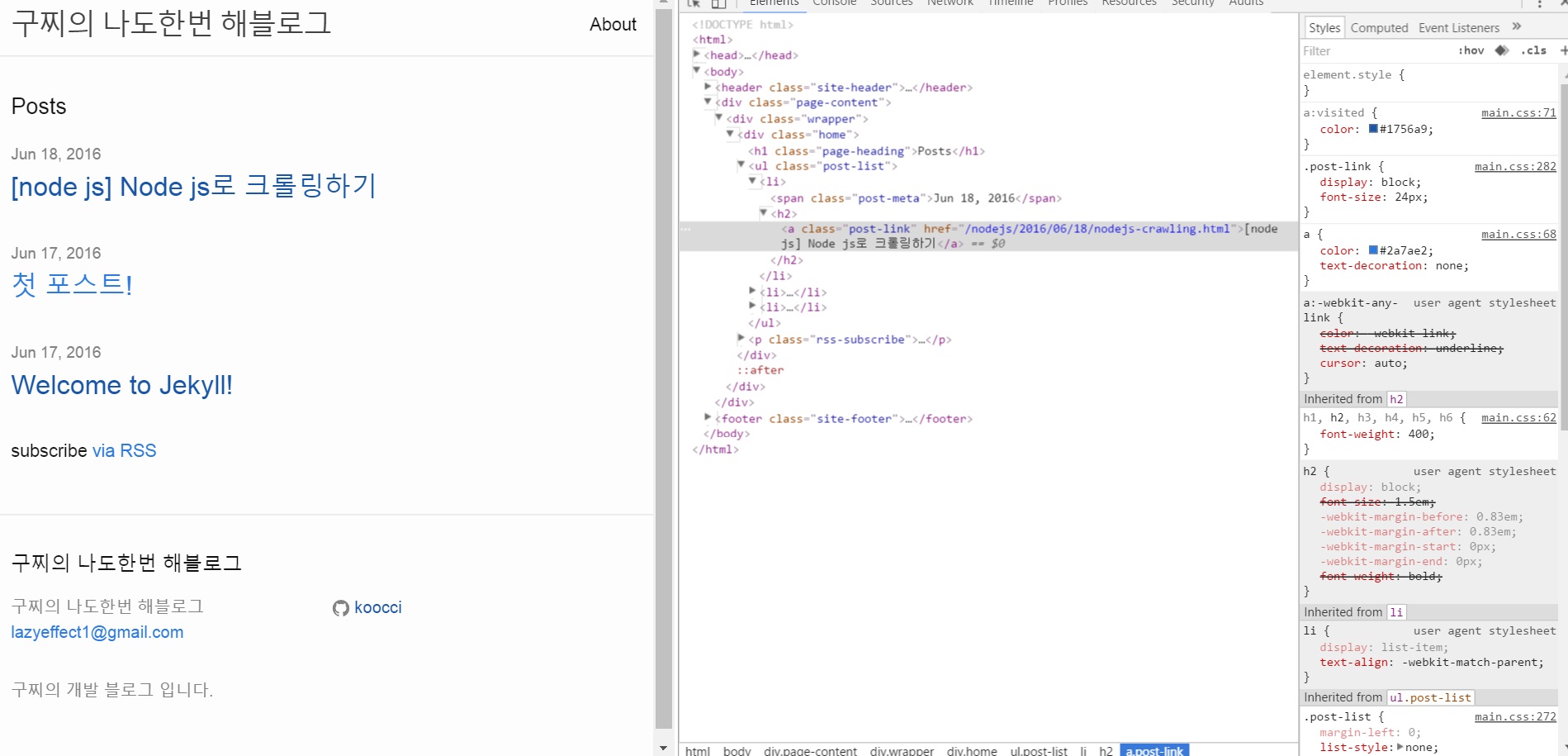
오른쪽에 개발자모드로 element들을 볼 수 있다.
기본 jekyll 버전이라 쉬울 것이다.
list 형식으로 <ul> 태그가 있고, class는 post-list라 돠어있다.
그리고 li 내부 post-meta로 날짜, post-link로 제목이 나와있다.
자 이제, 이 제목들을 크롤링 해보자.
BLOG Crawling
각자 사용하는 툴이 다르겠지만, 난 sublimeText3를 사용한다.
var request = require('request');
var options = {
encoding: "utf-8",
method: "GET",
uri: "http://localhost:4000/"
}
request(options, function(err,res,html){
console.log(html)
});기본적인 어구다.
우리가 기본적으로 사용할 모듈은 request 모듈이다.
자세한 내용은 request document를 참조하자.
위 코드를 보면 request 모듈의 역할이 무엇일지가 보인다.
바로 코드 내부에서 html소스를 불러온다는 것.
간단히 말하면 http요청을 볼 수 있는 client다.
위와 같이 option에는 여러가지 들어갈 수 있지만, encoding을 utf-8로 맞추고 uri등을 넣어주면 console에 아주 이쁘게 나온다.
자, 이제 이 console로 찍은 것들을 내가 컨트롤 할 수 있어야 한다.
var request = require('request');
var cheerio = require('cheerio');
var options = {
encoding: "utf-8",
method: "GET",
uri: "http://localhost:4000/"
}
request(options, function(err,res,html){
var $ = cheerio.load(html);
console.log($(".post-list a")[0].children[0].data);
});다음과 같이 하면?
[node js] Node js로 크롤링하기
라고 이쁘게 나온다.
cheerio 가 뭔지는 몰라도 밑에 console 구문은 반가워 보일 것이다.
일반적으로 jquery를 써봤다면 매우 비슷하다.
바로 cheeio가 그런 역할을 한다.
cheerio의 설명도 똑같이 되어 있다.
Fast, flexible, and lean implementation of core jQuery designed specifically for the server.
즉, 마치 jquery를 쓰듯이 node js 서버 내부적으로 사용이 가능한 것이다.
이런 식으로 모든 제목들, 날짜들도 크롤링 해볼 수 있다.
기본은 끝!
이미 기본적인 것들은 모두 끝났다.
위 기술만 있어도 간단한 크롤링은 다 할 수 있다고 본다.
물론 조금 더 깊이 들어가서 완전 자동화를 하려면 더 공부를 해야겠지만.. 내가 해왔던 프로젝트에서 크롤링을 할 때는 위 기술로 대부분 가능했다. (물론 조금 많이 손보기는 했다)
다음 포스팅에는 위에서 언급한 예시들을 한 두어개 써 볼 생각이다.