NetWork2
워낙 통신은 양이 많아서 2번으로 나누어서 정리해야 할 듯하다.
이번엔 네트워크 계층부터 하도록 하겠다.
네트워크 계층
네트워크 층 은 네트워크와 네트워크가 연결된 환경에서 데이터를 송신 호스트에서 수신 호스트로 배달하는 역할을 한다.
중간에 다양한 데이터 링크가 있어도 호스트 A에서 B로 데이터가 전달되는 것이 이 네트워크 층 때문이다.
실제로 데이터를 전송하기 위해서는 수신처의 주소, 즉, 어드레스가 필요하다.
이 주소는 통신을 하는 전 세계 네트워크에서 유일하게 사용된다.
IP
네트워크 계층에서 대표적인 것이 IP(Internet Protocol) 이다.
네트워크 계층의 역할을 한마디로 정의하자면, 종점 노드 간의 통신을 실현하는 것이다.
종점 노드 간 통신은 엔드 투 엔드(End-To-End) 통신이라고 하는데, 이는 네트워크 층에서 가장 중요한 역할을 한다.
네트워크 층 아래에 위치하는 데이터 링크층은 동일한 종류의 데이터 링크로 연결되어 있는 노드 간에만 패킷을 전송한다.
네트워크층은 통신 경로상에 있는 데이터 링크의 차이를 은폐해서 서로 다른 종류의 데이터 링크 사이를 이어주면서 패킷을 배송함으로써, 다른 데이터 링크로 연결된 컴퓨터 간에 통신이 가능하도록 한다.
IP의 중요 기능을 정리해보자.
1. IP 주소를 이용해서 최종 목적지에 데이터 전송
2. 라우팅(Routing)
먼저 IP는 호스트가 어떤 데이터링크에 연결되어 있는지와 상관없이 동일한 형식을 사용한다.
즉, 이더넷이든, 무선 LAN이든, PPP든 상관없이 IP 주소의 형식은 똑같다.
네트워크층에는 데이터링크층의 성질을 추상화 하는 기능이 있기 때문이다.
또한 브리지나 스위칭 허브와 같이 물리층이나 데이터 링크층에서 패킷을 중계하는 기기에는 IP주소를 설정할 필요가 없다.
이러한 기기는 IP패킷을 단순히 0이나 1로된 비트열로 전달하거나 데이터 링크 프레임의 데이터 부분으로 전송될 뿐이다.
IP는 커넥션리스형 이기 때문에 패킷을 송신하기 전에 통신 상대와의 커넥션을 확립하지 않는다.
상위층에 송신해야 하는 데이터가 발생하여 IP에게 송신 요청이 들어오면 바로 데이터를 IP 패킷으로 만들어 송신한다.
커넥션리스형인 경우 수신처 호스트의 전원이 꺼져 있거나 존재하지 않는 경우에도 패킷을 보낼 수 있다.
반대로 말하면, 언제, 누가 패킷을 보낼 것인지 알 수 없다.
따라서 항상 네트워크를 감시하다가 자기 앞으로 패킷이 전달되면 그것을 수신하여 처리해야 한다.
준비가 안된 경우에는 패킷을 놓칠 수도 있다.
그럼에도 IP에서 커넥션리스형을 쓰는 이유는 간략화 와 고속화 때문이다.
과정이 간략하고 속도가 빠르기 때문에 IP에서는 커넥션리스형을 쓴다.
IP 주소 는 4바이트, 즉 32비트로 표현된 숫자 집합이다.
IPv6의 경우는 16바이트, 즉 128비트로 표현된다.
IP는 호스트별이 아니라 NIC 별로 할당한다.
보통 NIC에 한개의 IP를 할당하지만, 여러개 역시 가능하고 보통 라우터는 2개 이상의 NIC를 갖고 있어서, 약 43억개가 가능한 IPv4로는 전세계 인구보다도 적은 수밖에 되지 않는다.
따라서, IPv6는 주소의 고갈을 염려해 만들어졌으나 여전히 IPv4를 기준으로 사용되고 있다.
IPv4 기준의 4바이트 IP주소는 네트워크 주소와 호스트(컴퓨터를 의미) 주소로 나뉘며, 주소의 형태에 따라서 A, B, C, D, E 클래스로 분류가 된다.
상세 내용은 아래 링크로 확인하자.
https://ko.wikipedia.org/wiki/IPv4
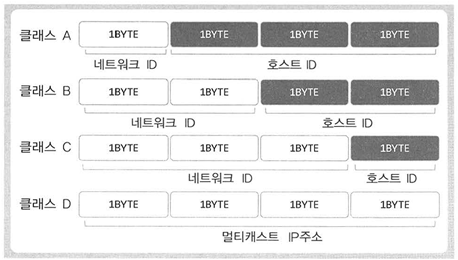
E 클래스는 예약되어 있는 주소체계로 생략하였다.
초기 IP에서는 네트워크부와 호스트부를 위와 같이 클래스로 나누었지만, 현재는 서브넷 마스크(네트워크 프리픽스) 로 대부분 나눈다.
그 이유는 클래스에는 낭비가 많기 때문이다.
클래스 B의 경우, 하나의 링크에 65000대의 호스트를 연결할 수 있다.
그러나 하나의 링크에 65000대의 컴퓨터를 연결하는 일은 거의 없다.
서브넷 마스크는 이진수라고 생각해야 한다.
32비트로 된 수치로, IP 주소의 네트워크부를 나타내는 비트에 대응하는 부분의 비트는 1로 되고, 호스트부를 나타내는 비트는 0이 된다.
따라서, 클래스에 구애받지 않고 IP 주소의 네트워크부를 정할 수 있게 되었다.
참고할 점은 IP주소에서 호스트부를 할당할 때, 모든 비트를 0이나 1로 할 수 없다.
0으로 하면 네트워크 주소(서브넷 마스크) 혹은 IP주소를 모르는 경우에 사용하도록 되어 있고, 모든 비트가 1인 경우는 브로드케스트 주소 가 된다.
네트워크 주소(네트워크 ID)란 네트워크의 구분을 위한 IP주소의 일부를 말한다.
예를 들어 WWW.SEMI.COM 이라는 회사의 무대리에게 데이터를 전송한다고 가정해보자.
그런데 이 회사의 컴퓨터는 하나의 로컬 네트워크로 연결되어있다.
그렇다면 먼저 SEMI.COM의 네트워크로 데이터를 전송하는 것이 우선이다.
즉, 처음부터 4바이트 IP주소 전부를 참조해서 무대리의 컴퓨터로 데이터가 전송되는 것이 아니라, 4바이트 IP주소 중에서 네트워크 주소만을 참조해서 일단 SEMI.COM의 네트워크로 데이터가 전송된다.
그리고 SEMI.COM의 네트워크로 데이터가 전송되었다면, 해당 네트워크는 전송된 데이터의 호스트 주소(호스트 ID)를 참조하여 무대리의 컴퓨터로 데이터를 전송해준다.
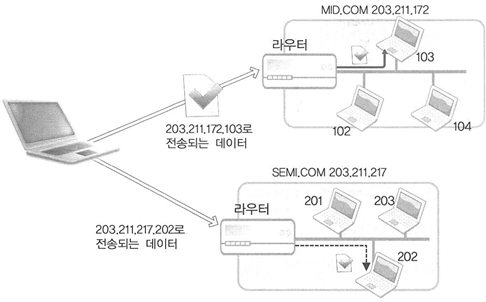
위 그림에서 보면 임의의 호스트가 203.211.172.103과 203.211.217.202로 데이터를 전송하고 있다.
그런데 이 중에서 203.211.172와 203.211.217이 네트워크 주소이다.
따라서 해당 네트워크로 데이터가 전송된다.
네트워크를 구성하려면 외부로부터 수신된 데이터를 호스트에 전달하고, 호스트가 전달하는 데이터를 외부로 송신해주는 물리적 장치가 필요한데, 이를 라우터 또는 스위치 라 한다.
따라서 네트워크로 데이터가 전송된다는 것은 네트워크를 구성하는 라우터(Router) 또는 스위치(Switch) 로 데이터가 전송됨을 뜻한다.
그러면 데이터를 전송 받은 라우터는 데이터에 적혀있는 호스트 주소를 참조하여 호스트에 데이터를 전송해준다.
IP 주소에서 어디까지가 네트워크 부인지 표시하기 위해 /24와 같은 CIDR(사이더) 표기를 사용한다.
또는 서브넷마스크(subnet mask) 라고 해서 255.255.255.0과 같이 표현하기도 한다.
브로드캐스트(broadcast) 주소 는 호스트에 할당해서는 안되는 특별한 IP 주소다.
브로드캐스트 주소로 보낸 패킷은 같은 네트워크의 모든 호스트에 전달된다.
브로드캐스트는 로컬 브로드캐스트 와 다이렉트 브로드캐스트 로 나누어진다.
자신이 속해 있는 링크 안의 브로드캐스트가 로컬 브로드캐스트다.
만약, 네트워크 주소가 192.168.0.0/24 인 경우, 브로드캐스트 주소는 192.168.0.255 가 된다.
이 브로드캐스트 주소가 설정된 IP패킷은 라우터에서 차단되기 때문에 192.168.0.0/24 외의 다른 링크에는 전달되지 않는다.
다른 IP 네트워크에 대한 브로드캐스트는 다이렉트 브로드캐스트 주소를 설정해야 한다.
예를 들어 192.168.0.0/24 안에 있는 호스트가 수신처 IP 주소를 192.168.1.255로 하여 IP 패킷을 송신했다고 가정하면 이 패킷을 수신한 라우터는 패킷을 목적으로 하는 네트워크 192.168.1.0/24로 전송한다.
이것으로 192.168.1.1 ~ 192.168.1.254 까지의 모든 호스트에게 패킷을 보낼 수 있다.
즉, 로컬일 경우 라우터에서 브로드캐스트를 다른 네트워크에 전송하지 않고 내부에만 전송한다.
다이렉트의 경우는 내부 호스트들은 패킷을 파기하고 라우터가 해당하는 네트워크로 전송을 한다.
멀티케스트 는 패킷을 특정 그룹에 소속된 모든 호스트에게 보낼 때 사용한다.
즉 내부 네트워크에도 보내고, 라우터에서 패킷을 복제해 그룹내 다른 네트워크에도 보낸다.
IP를 그대로 사용하므로 신뢰성은 보장되지 않는다.
브로드캐스트로 할때는 전체 단말에 패킷을 송신하고, 수신한 호스트의 IP보다 상위층에서 자신에게 필요한 데이터인지 판단하여 수취하거나 파기했었다.
이는 관계없는 네트워크나 호스트에게까지 영향을 끼치기 때문에 전체 트래픽을 증가시킨다.
또한 브로드캐스트는 라우터를 넘어갈 수 없기 때문에, 다른 세그멘트에도 동일한 패킷을 보내고 싶으면 별도의 장치가 필요했다.
그 결과, 라우터도 넘어갈 수 있고, 필요로 하는 그룹에게만 패킷을 송신하는 멀티캐스트는 매우 유용하다.
IP 멀티캐스트에는 클래스 D의 IP주소를 사용한다.
따라서 맨 앞의 4비트가 1110이면 멀티캐스트 주소로 식별한다.
그리고 나머지 28비트가 멀티캐스트의 대상이 되는 그룹 번호가 된다.
경로제어(Routing)
경로 제어(라우팅 : Routing) 는 수신처 IP 주소를 가진 호스트까지 패킷을 전달하기 위한 기능이다.
네트워크가 아무리 미로처럼 복잡해도 경로 제어에 의해 목적하는 호스트까지의 경로(루트)가 결정된다.
먼저 커널 공간에서 IP 처리 흐름을 보자.
생성된 TCP 세그먼트는 그대로 IP 처리에 돌입한다.
IP 계층에서는 최종 목적지가 적힌 IP 헤더를 TCP 세그먼트에 추가해서 IP 패킷을 생성한다.
헤더에는 목적지 IP 주소 외에 저장하고 있는 데이터 길이, 프로토콜 종류(TCP 등), 헤더 체크섬 등이 기록된다.
기본적으로 IP패킷은 TCP에 의해 링크 계층에서 최대 전송 크기로 분할돼 있기 때문에 여기에 IP 헤더만 추가한 것이다.
참고로, TCP 헤더는 20바이트, IPv4 헤더도 기본적으로 20바이트이기 때문에 이 시점에 IP 패킷은 1500바이트로 커져버린다.
그럼 최종 수신처의 호스트까지 패킷을 배송하는 과정을 알아보자.
홉(hop) 에는 뛰다라는 뜻이 있다.
TCP/IP에서는 IP 패킷이 네트워크 1구간을 뛰는 것을 홉 이라고 하며, 이 1구간을 1홉 이라 한다.
IP 경로 제어는 홉 바이 홉 라우팅이라는 방식을 사용한다.
즉, 1구간별로 그 다음 루트가 정해져 패킷이 전송된다.

1홉의 범위는 데이터 링크층 이하의 기능만을 이용해서 프레임이 전송되는 1구간을 의미한다.
이더넷과 같은 데이터 링크에서는 MAC 주소를 사용하여 프레임을 전송한다.
1홉은 송신처 MAC 주소와 수신처 MAC 주소를 사용하여 프레임이 전송되는 구간이 된다.
즉, 호스트나 라우터의 NIC에서 라우터에 의한 중계를 거치지 않고 도달할 수 있는 인접한 호스트나 라우터의 NIC까지의 구간을 말한다.
1홉 구간 안에서는 케이블이 브리지나 스위칭 허브로 연결되는 경우는 있어도, 라우터가 게이트웨이로 연결되는 경우는 없다.
홉 바이 홉 라우팅에서 라우터나 호스트는 IP 패킷에 다음 전송처가 되는 라우터나 호스트를 지시할 뿐, 최종 목적지까지의 경로를 지시하는 것은 아니다.
각 구간(홉)별로 각각의 라우터가 IP 패킷의 전송 처리를 하고, 그것을 반복하면서 최종 수신처의 호스트까지 도달하는 것이다.
즉, IP 주소를 이용해 대상 서버를 지정할 수 있다.
하지만 대상 서버가 항상 같은 네트워크 내에 있는 것은 아니다.
다른 네트워크에 있는 경우, 최종 목적지에 도달할 때까지 목적지를 알고 있는 라우터에 전송을 부탁한다.
IP 패킷을 바든 라우터는 해당 IP 패킷의 헤더에서 목적지를 확인해서 어디로 보내야 할지를 확인한다.
이때 사용되는 것이 라우팅 테이블(Routing Table) 이다.
경로 제어표 라고도 하는 라우팅 테이블은 모든 호스트와 라우터에 있다.
각자 자신이 알고 있는 목적지 정보를 라우팅 테이블이라 하는 형태로 목록화하여 가지고 있다.
라우팅 테이블은 사람이 직접 입력한 경로 정보(정적 경로 제어)나 자신의 서버에 설정된 IP 주소로 파악할 수 있는 정보(동적 경로 제어) 등 다양한 정보를 이용해 구성된다.
외부와 접속하는 네트워크는 보통 기본 게이트웨이(default gateway) 라는 라우터가 설치돼 있다.
A에서 E네트워크로 IP 패킷을 보내려고 할 때, IP 주소를 가지고 목적지가 E 네트워크임은 알 수있지만, 자신의 라우팅테이블에 목적지가 남아 있지 않기 때문에 네트워크 E라는 것을 알 수 없다.
이때, 기본 게이트웨이에 보내면 외부 네트워크에 접속되어 있어 외부로 패킷을 보낼 수 있다.
라우팅 테이블에서 IP 패킷을 송신할 때에는 IP 패킷의 수신처 주소를 조사 라우팅 테이블에서 일치하는 네트워크 주소를 검색하고, 대응하는 그 다음 라우터에게 패킷을 보낸다.
만약, 라우팅 테이블에 일치하는 네트워크 주소가 여러 개라면, 일치하는 비트열이 긴 네트워크 주소를 선택해야 한다.
이를 최장 일치라고 한다.
IP를 이용한 전송은 주변을 신뢰해야 성립한다.
각 라우터는 라우팅 테이블을 기반으로 패킷을 전송하므로, 도중에 있는 라우터가 잘못된 라우팅 테이블을 가지고 있으면 목적지가 바뀔 수 있다.
예를 들어, 네트워크 C와 네트워크 F 경계에 있는 라우팅 테이블에 오류가 있어서 네트워크 E에 가기 위해서 네트워크 A를 경유해야한다고 기술되어 있다고 하자.
그러면 해당 라우터는 A와 C사이에 있는 라우터에게 패킷을 준다.
이 패킷을 받은 라우터는 자신의 라우팅 테이블을 보고 다시 패킷을 되돌린다.
몇번이고 왕복을 하는 것이다.
이를 해결하기 위해 IP 헤더에는 TTL(Time To Live) 라는 생존 시간 정보를 가진다.
라우터를 하나 경유할 때마다 라우터가 TTL을 하나씩 줄여서 전송한다.
따라서, TTL이 0 이 되면 라우터가 패킷을 파기하게 되고, 패킷이 좀비가 되어 배회하게 되는 일을 방지한다.
IP 패킷이 도달할 라우터나 호스트에 도착하면, 해당 기기가 연결되어 있는 네트워크 인터페이스(데이터 링크)의 드라이버에게 IP 패킷을 전달하고, 실제 통신 처리를 한다.
통신처 기기의 MAC 주소를 모르는 경우, ARP(Address Resolution Protocol) 을 사용해 MAC 주소를 조사한다.
상대방의 MAC주소를 찾으면 이더넷 드라이버에게 MAC주소와 IP 패킷을 보내 송신 처리를 의뢰한다.
IP 분할 및 재구축
데이터 링크에 따라 최대 전송 속도(MTU)가 달라진다. (MTU에 대해서는 데이터링크 층의 설명을 참고하자.)
데이터 링크에 따라 MTU의 크기가 다른 것은 데이터 링크가 목적별로 만들어져 각각의 목적에 맞는 MTU의 크기가 정해져 있기 때문이다.
IP는 데이터 링크의 상위층이므로 데이터 링크의 MTU 크기에 좌우되어서는 안된다.
IP는 이렇게 데이터 링크별로 다른 성질을 추상화 하는 기능이 있다.
호스트나 라우터는 필요에 따라 IP 데이터그램의 분할 처리(Fragmentation : 프래그먼테이션) 를 해야 한다.
분할 처리는 네트워크에 데이터그램을 보내려고 할 때 그 크기대로 전송할 수 없는 경우에 한다.
예를 들어, 송신 호스트의 MTU가 4352라고 하자. (UDP 데이터 4324, UDP 헤더 8, IP 헤더 20)
송신 호스트에서 라우터로 패킷을 보내고, 라우터에서 수신 호스트로 보낼 때 이더넷을 사용한다고 하자.
이더넷의 MTU는 1500바이트(옥텟)이므로 4324바이트의 IP 데이터그램을 하나의 프레임으로 보낼 수 없다.
따라서 라우터가 IP 데이터그램을 3개로 분할하여 보내게 된다.
이 분할 처리는 필요할 때마다 몇번이든 반복한다. (8바이트의 배수 단위로 이루어진다.)
분할된 IP 데이터그램(패킷)을 원래의 IP 데이터그램으로 되돌리는 재구축 처리는 맨 끝에 있는 수신처 호스트에서만 이루어진다.
중간에 있는 라우터는 분할 처리는 하지만 재구축 처리는 하지 않는다.
이는 많은 이유가 있는데, 예를 들어 분할한 IP 데이터그램이 동일한 경로를 통해 도착한다는 보장이 없다.
그래서 도중에 기다리고 있더라도 패킷이 도착하지 않을 수 있다.
또한 분할된 단편이 도중에 분실되어 도착하지 않을 수 있다.
더욱이 도중에 재구축을 하더라도 또 다른 라우터를 통과할 때 분할 처리를 해야 하는 경우도 있을 수 있다.
결국 세세한 제어가 오히려 라우터에 부담을 줄 수 있어, 재구축 처리는 종점에서만 한다.
분할 처리에는 몇 가지 단점이 있다.
첫 번째는 라우터의 처리가 무거워진다.
시간이 지나면서 네트워크의 물리적인 전송 속도도 점점 향상되고 있기 때문에, 네트워크의 전송 속도에 맞추어 라우터의 고속화도 요구된다.
한편 보안 향상을 위한 필터링 처리(특정 파라미터를 가진 IP 데이터그램 외에는 라우터를 통과할 수 없도록 하는 것) 등과 같이 라우터가 해야할 처리가 늘어나고 있다.
IP 분할 처리도 라우터에 있어서 큰 부하다.
따라서 라우터에서는 분할 처리를 하지 않는 게 좋다.
두번째로 분할 처리를 하면 분할된 단편 하나를 분실했을 때, 원래 IP 데이터그램 전체가 손상된다는 것이다.
초기 TCP에서는 이러한 상태를 막기 위해 분할하지 않은 작은 크기로 패킷을 보내게 되었고, 그 결과 네트워크 효율이 떨어졌다.
따라서, 이를 막기 위해 경로 MTU 탐색(Path MTU Dscovery) 을 한다.
경로 MTU(PMTU : Path MTU) 란, 송신처 호스트에서 수신처 호스트까지 분할 처리를 할 필요가 없는 최대 MTU를 말한다.
즉, 경로에 의존하는 데이터 링크의 최소 MTU가 된다.
경로 MTU 탐색은 경로 MTU를 발견하고 송신처 호스트에서 경로 MTU의 크기로 데이터를 분할한 후 송신하는 방법을 사용한다.
경로 MTU 검색을 하면 도중에 있는 라우터에서 분할 처리를 할 필요가 없고 TCP도 보다 큰 패킷 크기로 데이터를 보낼 수 있게 된다.
경로 MTU 탐색의 처리과정은 다음과 같다.
먼저, 송신 호스트에서는 IP 데이터그램을 보낼 때에 IP 헤더 안의 분할 금지 플래그를 1로 설정한다.
이 때문에 도중에 있는 라우터는 IP 데이터그램의 분할 처리를 해야 할 경우에도 분할 처리를 하지 않고 패킷을 그냥 파기한다.
그리고 ICMP 도착 불능 메시지를 사용해 데이터 링크의 MTU 값을 송신 호스트에게 통지한다.
이후, 동일한 수신처로 보낼 IP 데이터그램에서는 ICMP의 의해 통지받은 경로 MTU 값을 MTU로써 사용한다.
송신 호스트에서는 그 값을 바탕으로 분할 처리한다.
이 조작을 반복해 ICMP 도착 불능 메시지가 반환되지 않으면 수신 호스트까지의 경로 MTU를 얻게 된다.
TCP의 경우, 경로 MTU의 크기를 바탕으로 최대 세그먼트 길이(MSS)의 값을 재계산하고 그 값을 바탕으로 패킷 송신이 일어난다.
ARP
IP 주소가 정해지면 수신처 IP 주소로 IP 데이터그램을 보낼 수 있다.
그런데 실제로 데이터링크를 이용해 통신할 때는 IP 주소에 대응하는 MAC 주소가 필요하다.
ARP 는 주소 해결을 위한 프로토콜이다.
수신처 IP 주소를 단서로 다음에 패킷을 받아야 할 기기의 MAC 주소를 알고 싶을 때 사용한다.
수신처 호스트가 동일 링크상에 없는 경우에는 다음 홉의 라우터 MAC 주소를 ARP로 조사한다.
ARP는 IPv4에서만 사용된다.
호스트 A가 B로 패킷을 보내고 싶지만 MAC 주소를 모른다면, IP 주소로부터 MAC주소를 알아내기 위해 ARP 요청 패킷을 보낸다.
그럼 B에서 자신의 MAC 주소를 반송하는데 이것이 ARP 응답 패킷이다.
그럼 MAC주소와 IP주소가 둘다 필요한 이유가 무엇일까?
그 이유는 다른 링크에 연결된 호스트에 패킷을 보낼 때를 생각하면 이해할 수 있다.
호스트 A에서 호스트 B에 IP 데이터그램을 보낼 때, 중간의 C 라우터를 경유해야 한다고 하자.
호스트 B의 MAC 주소를 알고 있더라도 C 라우터에서 네트워크가 끊어져 있기 때문에 직접 송신할 수 없다.
따라서, 먼저 C 라우터의 MAC주소앞으로 패킷을 송신해야한다.
만일 MAC 주소를 브로드캐스트 주소로 하면, 또 다른 D 라우터도 패킷을 수신하고, 그러면 D 라우터는 C 라우터로 패킷을 다시 송신하므로, 중복될 수 있다.
이더넷상에서 IP 패킷을 송신할 때는 다음에 어떤 라우터를 경유하여 패킷을 송신할 것인가? 라는 정보가 필요하다.
그리고 다음 라우터에는 MAC 주소로 도착할 수 있다.
만일 MAC 주소만으로 전 세계 네트워크의 모든 호스트를 연결한다면, 이는 너무 많은 트래픽이 쌓일 수 밖에 없다.
즉, 전 세계 MAC 주소를 브리지가 학습하면, 저장해야 할 MAC주소가 너무 많아질 것이다.
정리하면 ARP의 필요성은 다음과 같다.
- 송신자는 목적지(수신자)의 IP주소를 알고 있다.
- IP 데이터그램을 프레임으로 캡슐화하여 전송하려고 한다.
- 그러나 프레임 헤더에는 물리주소가 들어가야 하는데 물리주소를 모른다.
- 따라서, IP주소를 이용하여 물리주소를 알아내는 방법이 필요하게 되었다.
ⅰ. 송신자는 목적지 IP주소는 알고 있으나, 물리주소는 모름.
ⅱ. 물리주소를 알아내기 위해 ARP 요청 메시지 생성.
= ARP 요청 메시지 (송신자 물리주소, 송신자 IP주소, 00-00-00-00-00, 수신자 IP주소)
ⅲ. 요청메시지를 데이터링크 계층으로 전달, 프레임 생성.
= 송신자 물리주소를 발신지 주소, 수신자 물리주소를 브로드캐스트 주소로 지정
ⅳ. 모든 호스트나 라우터는 이 프레임을 수신하여 자신의 ARP로 전달.
ⅴ. 요청 메시지에 해당되는 호스트나 라우터만 ARP응답 메시지 생성.
= 자신의 물리주소를 포함하는 응답 메시지
ⅵ. ARP 응답메시지를 유니캐스트로 ARP 요청 메시지를 보낸 송신자에게 전송.
= 유니캐스트를 이요오하는 이유는 송신자가 요청메시지에 물리주소를 포함했기 때문
ⅶ. 송신자는 ARP 응답메시지를 받고 목적지 물리주소를 획득
ⅷ. 목적지에게 전송할 IP데이터그램을 획득한 물리주소를 이용해 프레임으로 캡슐화
ⅸ. 캡슐화된 프레임을 유니캐스트로 목적지로 전송
출처 : http://egloos.zum.com/Esunny/v/4052993
만약 ARP 테이블과 라우팅 테이블이 헤깔린다면 다음 자료를 보자.
데이터 링크 층 + 물리 층
데이터 링크(네트워크 인터페이스) 층 은 이더넷과 같은 데이터 링크를 이용하여 통신을 하기 위한 인터페이스가 되는 계층이다.
즉, NIC를 작동시키기 위한 디바이스 드라이버라고 생각해도 된다.
디바이스 드라이버는 OS와 하드웨어를 이어주는 소프트웨어다.
통신은 실제로 물리적인 통신 매체를 사용하여 일어난다.
데이터 링크층은 통신 매체에 직접 연결된 기기 사이에 데이터를 주고받을 수 있도록 하는 역할을 한다.
물리층에서는 데이터의 0과 1을 전압이나 빛의 펄스로 변환하여 물리적인 통신 매체에 흘려보낸다.
직접 연결한 기기 간에서도 주소를 이용하는 경우가 있다.
이러한 주소를 MAC 주소, 물리 주소, 하드웨어 주소 라고 한다.
이 주소는 동일한 통신 매체에 연결된 기기를 식별하기 위한 것이다.
이 MAC 주소 정보를 포함한 헤더가 네트워크층으로부터 받은 데이터에 붙여져 실제 네트워크로 흘러갑니다.
네트워크 층이든, 데이터 링크 층이든 주소를 근거로 데이터를 수신처까지 전달한다는 점은 같지만, 네트워크 층은 최종 목적지까지의 데이터의 배달을 담당하고, 데이터 링크층은 한 구간의 데이터 배달을 담당한다.
커널 공간 에서의 이더넷 처리 흐름을 보자.
IP 계층에서 라우팅 테이블을 통해 어떤 링크(NIC)가 패킷을 보낼 지 정해져 있다.
최종적인 통신 상태가 동일 네트워크 내에 있으면, 해당 서버에 직접 전송하지만, 다른 네트워크에 있으면 기본 게이트웨이에 패킷을 보내야 한다.
여기서 MAC 주소를 사용한다.
이더넷 헤더에는 이 MAC 주소를 목적지로 기입한다.
단, 여기서 적히는 것은 동일 링크 내에 있는 장비의 MAC주소다.
IP주소에 라우팅 테이블이 있었던 것처럼 MAC 주소에는 ARP 테이블(MAC 테이블)이 있다.
동일 링크 내의 노드에 대해서 IP주소 A에 대응하는 것은 MAC 주소 B다와 같은 형식으로 대응관계를 표현해 두었다.
IP로부터 전송받은 IP패킷은 이더넷 드라이버에서 보면 단순한 데이터에 지나지 않는다.
이 데이터에 이더넷 헤더를 붙여 송신처리를 수행한다.
이더넷 헤더는 수신처의 MAC 주소와 송신처의 MAC 주소, 이더넷 헤더에 이어지는 데이터의 프로토콜을 나타내는 이더넷 타입이 기술되어 있다.
이렇게 인접한 장비의 MAC주소를 헤더에 기록한 후 최종적으로는 OS가 버스를 통해 NIC에게 전달한다.
NIC는 이것을 다시 네트워크에 전송한다.
송신 중에 FCS가 하드웨어에서 계산되어 패킷의 마지막에 붙여진다.
이 FCS는 노이즈 등으로 패킷의 손상을 검출한다.
이더넷 등 해당 링크 층에서 하나의 프레임으로 전송할 수 있는 최대 크기를 MTU(Maximum Transfer Unit) 이라 한다.
링크 종류에 따라 다르지만, 이더넷 기준으로 1500바이트로 설정된다.
TCP의 MSS를 떠올려보면 링크 계층 크기에 따라 변동된다고 했는데, 바로 MTU에 따라 변동되는 것이다.
MTU에서 IP 및 TCP 헤더를 빼면 TCP의 MSS다.
전체 통신 정리
어떻게 통신이 이루어지는 지는 다른 사람의 글을 빌리겠다.
출처 : https://m.blog.naver.com/goduck2/220111709554
1) PC0에서 통신할 상대방 PC1의 IP 주소를 알아낸다.
2) PC1과 통신하기 위해서 메시지를 전송한다.
- 예를 들어 PC1으로 ping을 하거나, 메신저를 이용하여 메시지를 전송한다.
3) Routing Table에서 PC1의 IP 주소로 가려면, 어떤 interface로 나가야 하고, next hop IP가 무엇인지 찾는다.
4) Next hop IP의 MAC address가 ARP Table 에 등록되어 있는지 찾는다.
5) ARP Table에 Next hop IP의 MAC address가 없다면 MAC address를 알아오기 위해서 ARP request 메시지를 전송한다.
6) Swtich는 ARP request 메시지를 수신하면 source MAC address를 보고, PC0의 MAC Table entry를 만든다.
- PC0의 MAC address와 Frame이 수신된 port 번호를 MAC Table에 기록한다.
7) Switch는 ARP request 메시지를 모든 LAN port로 전송(브로드캐스트) 한다. ARP 패킷은 LAN 구간 끝까지 어디든지 날라간다.
8) ARP request를 수신한 PC1은 자신의 ARP Table에 PC0의 IP와 MAC address를 등록하고 ARP reply 메시지를 전송한다.
- PC1의 Routing Table에 PC0에 대한 routing entry가 등록되어 있지 않다면 PC1은 ARP reply를 전송 할 수 없다.
- PC1의 ARP Table에는 ARP request 메시지를 받으면서 이미 PC0의 MAC address가 등록되어 있다.
9) Swtich는 ARP reply 메시지를 수신하면, source MAC address를 보고, PC1의 MAC Table entry를 만든다.
10) PC0은 ARP reply 메시지를 수신하면, ARP Table에 PC1의 IP와 MAC address를 등록하고, PC1으로 전송되어야 할 패킷의
Destination MAC에 PC1의 MAC address를 부착하고 메시지를 전송한다.
11) Switch는 PC0가 전송한 Ethernet Frame을 수신하면, Desitnation MAC address가 MAC Table에 존재하는지 찾는다.
12) Switch는 MAC Table에 PC1의 정보가 등록되어 있으므로 PC1이 연결되어 있는 port로 메시지를 전송(Unicast)한다.
13) PC1은 Destination MAC address가 자신의 NIC MAC address와 동일하므로 메시지를 수신하여 IP layer로 전달하고,
IP layer에는 Destination IP가 자신의 IP와 동일하므로 IP 패킷을 수신한다.
이렇게 통신쪽을 정리해 보았다.